Dữ liệu đánh lừa
Dữ liệu không nói dối nhưng bạn đã bị lừa
Trong thiết kế sản phẩm và kinh doanh, rất hay thấy team dựa vào số liệu thô từ khảo sát/experiment để ra quyết định nhanh — nhưng kết luận vội thường sai vì quyết định dựa trên tỉ lệ tổng hợp mà bỏ qua cấu trúc dữ liệu. Đây là lỗi phổ biến mà tôi hay thấy gặp ở các bạn junior/mid: Không quan sát kỹ các phân lớp hay đặc tính trong bối cảnh của vấn đề (classification) và các biến gây nhiễu (noise).
Bài toán tiêu biểu
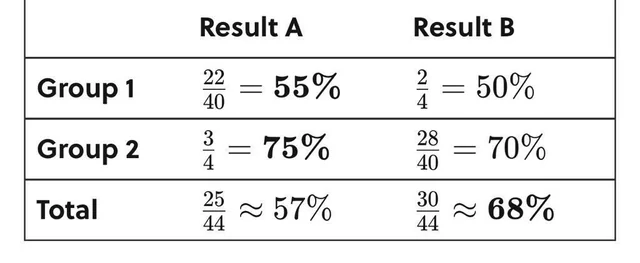
Giả sử bạn so sánh hai chiến dịch khuyến mãi A và B trên khách hàng dùng thẻ:
- Trong nhóm khách hàng doanh nghiệp, A chuyển đổi tốt hơn B.
- Trong nhóm khách hàng cá nhân, A cũng chuyển đổi tốt hơn B.
Nhưng khi gộp toàn bộ dữ liệu lại, B lại có tỉ lệ chuyển đổi cao hơn.
Vì sao? Vì tỉ lệ phân bổ chiến dịch khác nhau giữa các nhóm khách hàng (ví dụ B tập trung nhiều vào nhóm cá nhân có quy mô lớn), dẫn tới trọng số mẫu (weights) làm đảo chiều kết quả tổng thể.
Đây chính là Simpson’s paradox 1.
Simpson’s paradox
Khi tỉ lệ kết quả được tính là bình quân gia quyền theo kích thước từng nhóm, sự khác biệt về kích thước mẫu giữa các nhóm có thể khiến kết quả tổng hợp trái ngược với kết quả của từng nhóm riêng lẻ 2.
Để minh họa, xét hai nhóm với tỉ lệ thành công:
- Quan sát thứ nhất ở 2 nhóm: $A_{1,2}/B_{1,2}$ (có $A_{1,2}$ lựa chọn từ mẫu quan sát $B_{1,2}$)
- Quan sát thứ hai ở 2 nhóm: $C_{1,2}/D_{1,2}$ (có $C_{1,2}$ lựa chọn từ mẫu quan sát $D_{1,2}$)
Tỉ lệ tổng hợp tổng số lựa chọn trên tổng số quan sát: $(A_{1,2}+C_{1,2})/(B_{1,2}+D_{1,2})$
Simpson’s paradox xảy ra khi so sánh 2 kết quả (thay đổi góc nhìn): \(\frac{A_1}{B_1} > \frac{C_1}{D_1} \text{ và } \frac{A_2}{B_2} > \frac{C_2}{D_2}\)
nhưng: \(\frac{A_1+A_2}{B_1+B_2} < \frac{C_1+C_2}{D_1+D_2}\)
Nguyên nhân: chúng ta cư xử với thông tin ở mẫu quan sát khác nhau sẽ cho kết quả khác nhau, thường do các biến gây nhiễu tiềm ẩn gây ra.
Xem thêm các ví dụ điển hình khác 3.
👉 Vì vậy luôn kiểm tra kết quả ở mức phân lớp trước khi tin vào số liệu tổng hợp
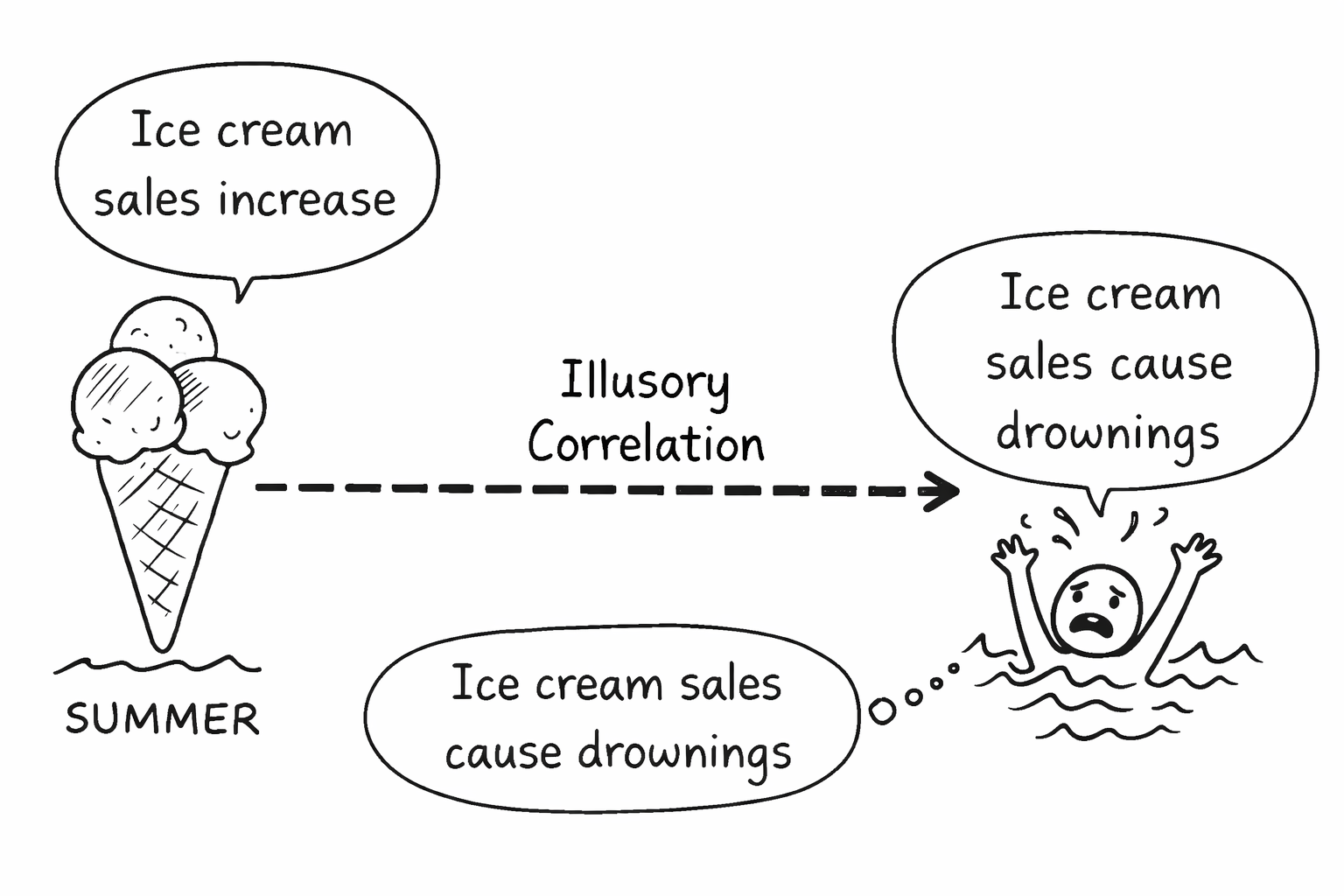
Nguyên nhân tâm lý học: Illusory Correlation
Con người có xu hướng nhìn thấy mối quan hệ nơi thực tế không tồn tại (illusory correlation4). Chỉ cần vài con số nổi bật, chúng ta dễ suy diễn thành quan hệ nhân quả và trở nên quá tự tin khi trình bày key findings.
Khắc phục
Áp dụng các kỹ thuật trích chọn đặc trưng (feature engineering) trong khoa học dữ liệu, loại bỏ các giá trị ngoại lai (outlier) và biểu diễn matrix correlation để xác định các key target.
- Phân biệt rõ: Correlation ≠ Causation.
- Luôn phân tích theo lớp (classification): user segment, channel, cohort…
- Sử dụng phân tích đa biến: regression (logistic / linear) để điều chỉnh trọng số và ước lượng ảnh hưởng có điều kiện.
- Quan tâm đến p-value / confidence interval, nhưng cũng đánh giá effect size và ý nghĩa thực tiễn.
Quy trình đúng nên là:
1. Quan sát correlation từ dữ liệu
2. Hình thành hypothesis H0
3. Kiểm chứng bằng toán thống kê (mức độ tự tin p_value < 0.05) hoặc A/B test hoặc causal inference
Tóm lại
Hai bước tìm correlation và đúc kết insight là hai công đoạn độc lập, không nên trộn và lẫn vội vã kết luận khi quan sát chưa đủ.
-
Simpson, E. H. (1951) — The interpretation of interaction in contingency tables ↩
-
Bickel, Hammel & O’Connell (1975) — Berkeley admission case ↩
-
Judea Pearl — Causal Inference (DAGs, causal reasoning) ↩
-
Why do we think some things are related when they aren’t?, thedecisionlab.com ↩
{kind=link}