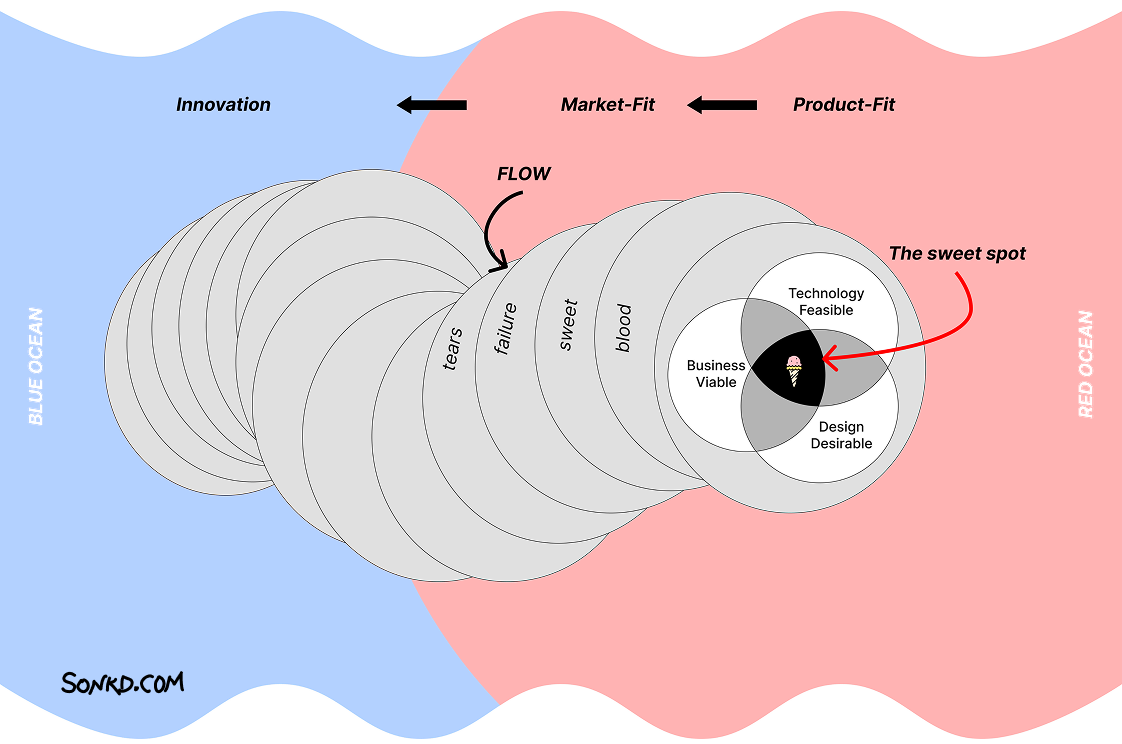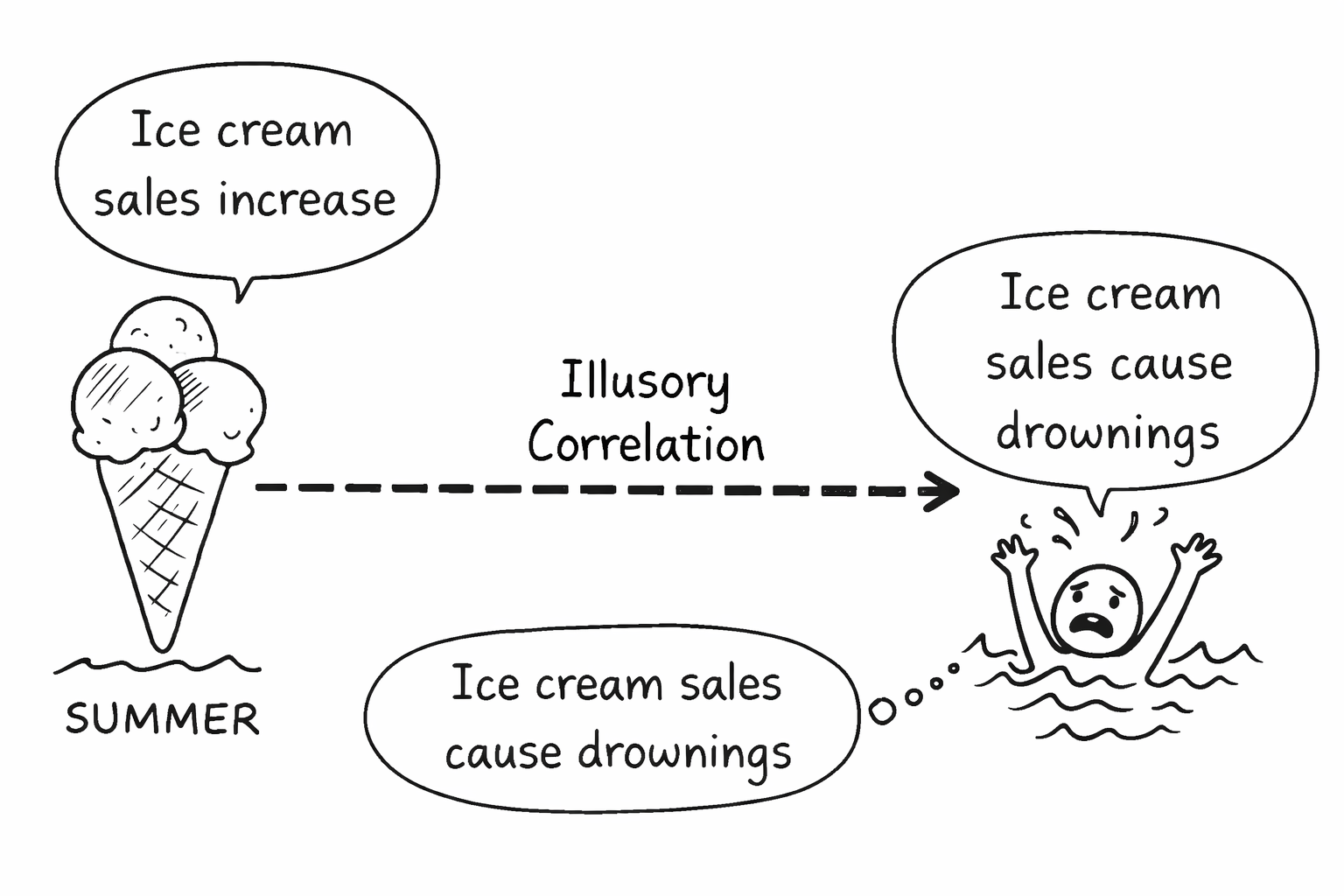
Dữ liệu không nói dối nhưng bạn đã bị lừa
Trong thiết kế sản phẩm và kinh doanh, rất hay thấy team dựa vào số liệu thô từ khảo sát/experiment để ra quyết định nhanh — nhưng kết luận vội thường sai vì quyết định dựa trên tỉ lệ tổng hợp mà bỏ qua cấu trúc dữ liệu. Đây là lỗi phổ biến mà tôi hay thấy gặp ở các bạn junior/mid: Không quan sát kỹ các phân lớp hay đặc tính trong bối cảnh của vấn đề (classification) và các biến gây nhiễu (noise).
Bài toán tiêu biểu
Giả sử bạn so sánh hai chiến dịch khuyến mãi A và B trên khách hàng dùng thẻ:
- Trong nhóm khách hàng doanh nghiệp, A chuyển đổi tốt hơn B.
- Trong nhóm khách hàng cá nhân, A cũng chuyển đổi tốt hơn B.
Nhưng khi gộp toàn bộ dữ liệu lại, B lại có tỉ lệ chuyển đổi cao hơn.
Vì sao? Vì tỉ lệ phân bổ chiến dịch khác nhau giữa các nhóm khách hàng (ví dụ B tập trung nhiều vào nhóm cá nhân có quy mô lớn), dẫn tới trọng số mẫu (weights) làm đảo chiều kết quả tổng thể.
Đây chính là Simpson’s paradox 1.
-
Simpson, E. H. (1951) — The interpretation of interaction in contingency tables ↩
...
Xem đầy đủ